2026
Learning to Factorize and Adapt: A Versatile Approach Toward Universal Spatio-Temporal Foundation Models
Siru Zhong, Junjie Qiu, Yangyu Wu, Yiqiu Liu, Yuanpeng He, Zhongwen Rao, Bin Yang, Chenjuan Guo, Hao Xu, Yuxuan Liang# (# corresponding author)
Submitted to IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI). Under review.
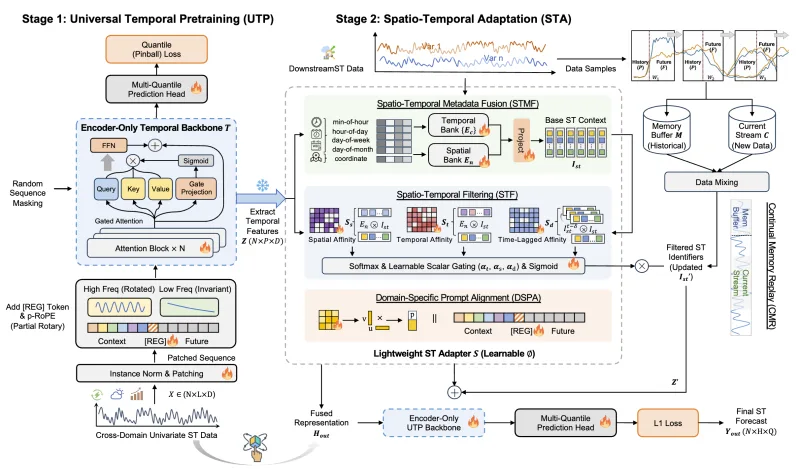
Spatio-Temporal (ST) Foundation Models (STFMs) promise cross-dataset generalization, yet joint ST pretraining is computationally expensive and grapples with the heterogeneity of domain-specific spatial patterns. Substantially extending our preliminary conference version [1], we present FactoST-v2, an enhanced factorized framework redesigned for full weight transfer and arbitrary-length generalization. FactoST-v2 decouples universal temporal learning from domain-specific spatial adaptation. The first stage pretrains a minimalist encoder-only backbone using randomized sequence masking to capture invariant temporal dynamics, enabling probabilistic quantile prediction across variable horizons. The second stage employs a streamlined adapter to rapidly inject spatial awareness via meta adaptive learning and prompting. Comprehensive evaluations across diverse domains demonstrate that FactoST-v2 achieves state-of-the-art accuracy with linear efficiency—significantly outperforming existing foundation models in zero-shot and few-shot scenarios while rivaling domain-specific expert baselines. This factorized paradigm offers a practical, scalable path toward truly universal STFMs.
Learning to Factorize and Adapt: A Versatile Approach Toward Universal Spatio-Temporal Foundation Models
Siru Zhong, Junjie Qiu, Yangyu Wu, Yiqiu Liu, Yuanpeng He, Zhongwen Rao, Bin Yang, Chenjuan Guo, Hao Xu, Yuxuan Liang# (# corresponding author)
Submitted to IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI). Under review.
Spatio-Temporal (ST) Foundation Models (STFMs) promise cross-dataset generalization, yet joint ST pretraining is computationally expensive and grapples with the heterogeneity of domain-specific spatial patterns. Substantially extending our preliminary conference version [1], we present FactoST-v2, an enhanced factorized framework redesigned for full weight transfer and arbitrary-length generalization. FactoST-v2 decouples universal temporal learning from domain-specific spatial adaptation. The first stage pretrains a minimalist encoder-only backbone using randomized sequence masking to capture invariant temporal dynamics, enabling probabilistic quantile prediction across variable horizons. The second stage employs a streamlined adapter to rapidly inject spatial awareness via meta adaptive learning and prompting. Comprehensive evaluations across diverse domains demonstrate that FactoST-v2 achieves state-of-the-art accuracy with linear efficiency—significantly outperforming existing foundation models in zero-shot and few-shot scenarios while rivaling domain-specific expert baselines. This factorized paradigm offers a practical, scalable path toward truly universal STFMs.
2025
Learning to Factorize Spatio-Temporal Foundation Models
Siru Zhong, Junjie Qiu, Yangyu Wu, Xingchen Zou, Bin Yang, Chenjuan Guo, Hao Xu, Yuxuan Liang# (# corresponding author)
Neural Information Processing Systems (NeurIPS) 2025 Spotlight
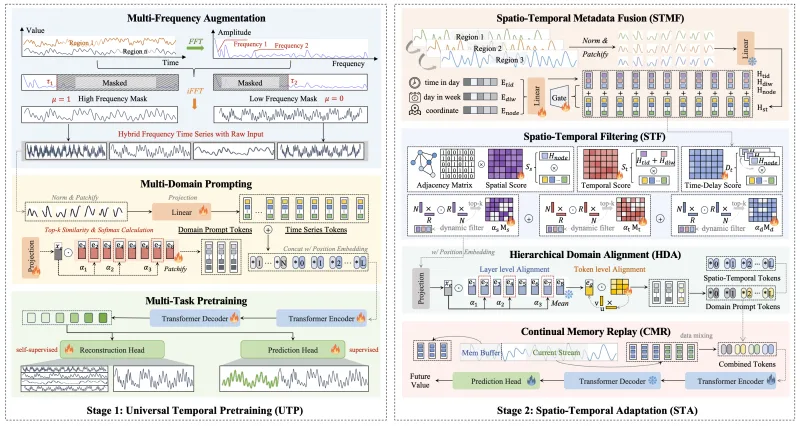
Spatio-Temporal (ST) Foundation Models (STFMs) promise cross-dataset generalization, yet joint ST pretraining is computationally costly and struggles with domain-specific spatial correlations. To address this, we propose FactoST, a factorized STFM that decouples universal temporal pretraining from ST adaptation. The first stage trains a space-agnostic backbone via multi-task learning to capture multi-frequency, cross-domain temporal patterns at low cost. The second stage attaches a lightweight adapter that rapidly adapts the backbone to specific ST domains via metadata fusion, interaction pruning, domain alignment, and memory replay. Extensive forecasting experiments show that in few-shot settings, FactoST reduces MAE by up to 46.4% versus UniST, uses 46.2% fewer parameters, achieves 68% faster inference than OpenCity, and remains competitive with expert models. This factorized view offers a practical, scalable path toward truly universal STFMs.
Learning to Factorize Spatio-Temporal Foundation Models
Siru Zhong, Junjie Qiu, Yangyu Wu, Xingchen Zou, Bin Yang, Chenjuan Guo, Hao Xu, Yuxuan Liang# (# corresponding author)
Neural Information Processing Systems (NeurIPS) 2025 Spotlight
Spatio-Temporal (ST) Foundation Models (STFMs) promise cross-dataset generalization, yet joint ST pretraining is computationally costly and struggles with domain-specific spatial correlations. To address this, we propose FactoST, a factorized STFM that decouples universal temporal pretraining from ST adaptation. The first stage trains a space-agnostic backbone via multi-task learning to capture multi-frequency, cross-domain temporal patterns at low cost. The second stage attaches a lightweight adapter that rapidly adapts the backbone to specific ST domains via metadata fusion, interaction pruning, domain alignment, and memory replay. Extensive forecasting experiments show that in few-shot settings, FactoST reduces MAE by up to 46.4% versus UniST, uses 46.2% fewer parameters, achieves 68% faster inference than OpenCity, and remains competitive with expert models. This factorized view offers a practical, scalable path toward truly universal STFMs.